Framework 01
Agent Factors Engineering (AFE)
The claim
Software has a new class of user. AI agents can navigate, extract information from, and take actions within software — but only if that software is designed to be understood and operated by a machine. Most software today is designed only for humans.
From HFE to AFE
Human Factors Engineering emerged in the 1940s from aviation and military research. The discipline's core insight was that system failures attributed to "human error" were usually failures of system design — the system had been built without adequate understanding of the humans who would operate it. HFE produced a set of principles — feedback, consistency, error prevention, recovery, progressive disclosure — that became foundational to every discipline of design that followed.
Sixty years later, software has a new class of operator: AI agents. These agents don't read — they parse. They don't navigate — they query. They don't form mental models — they build contextual representations. And they fail not because of cognitive load or attention limits, but because of ambiguity, inconsistency, invisible state, and missing structure.
HFE asked: what does the human need to understand and operate this system? AFE asks: what does the agent need to understand and operate this system? The questions are structurally identical. The answers are different.
The 8 AFE Principles
.well-known descriptor — that agents can access without parsing the visual interface.Agentability Score and tiers
Each principle is scored 0–100 based on automated checks and LLM-based evaluation. The composite score determines the site's Agentability Tier.
| Tier | Score | What it means |
|---|---|---|
| Agent-Ready | ≥ 45 | Agents can operate this software reliably |
| Developing | 35–44 | Partial agent operability with significant gaps |
| Lagging | 20–34 | Limited agent operability; most tasks will fail |
| Agent-Blind | < 20 | Software is effectively opaque to agents |
The scoring rubric is evolving toward v1. Most production software scores in the Lagging range today. Run an audit at agentability.io →
Framework 02
Agent-First UX Patterns
The claim
Designing for human supervision of AI is not primarily a safety problem. It is a design problem. The patterns that make human-AI collaboration safe and legible are UX decisions — about when to pause, how to communicate intent, and what to surface when the agent is done.
These four patterns emerged from A1OS, an agent-first operating system prototype built to make them concrete and demonstrable. They are now being ported into icuboid Studio.
Autonomy is not binary. It is a spectrum that the system governs based on the consequence of the next action. The design question is not "should the agent be autonomous?" — it is "what level of autonomy is appropriate for this action, for this agent, in this context?"
In practice: the system classifies actions by risk. High-consequence actions — executing a shell command, calling an external API, writing to a file — trigger a pause and surface an approval card. The human approves, edits the proposed action, or rejects with feedback. Lower-consequence actions proceed without interruption. Trust is earned through demonstrated reliability, not granted by default.
Agents must communicate what they are doing, why, and what they intend to do next — at an appropriate level of abstraction for the human watching. Maximum transparency is not the same as legible transparency. A human watching raw execution logs sees events without meaning. A human watching a plain-language step timeline sees what is actually happening.
In practice: plain-language timeline cards summarise agent actions in human terms. Raw logs and telemetry are available behind a toggle for users who need them. The interface communicates the shape of what the agent is doing, not every step.
Users care about what was produced, not every intermediate step. An agent that writes a script, encounters an error, installs a missing package, and retries has taken five steps. The user cares about one thing: did it run, and what did it produce?
Designing for outcomes means the interface's primary metaphor is deliverables, not steps. Files, not logs. Things that exist after the process, not a transcript of the process. Each agent session gets its own workspace. When the agent finishes, it declares its output files, which render as artifact cards with previews.
When an agent completes a task, it must explicitly return control to the human. Handback is not the absence of agent activity — it is a designed moment. Without a designed handback, the agent simply stops, and the human is left to determine what was done, what was produced, and what the current state of the world is.
Accountable handback means the agent summarises: what I did, what I made, where it is, what I'm uncertain about. This summary is elevated — pinned, not buried in the conversation thread or lost in the log.
Framework 03
The Mutual Legibility Thesis
The core idea
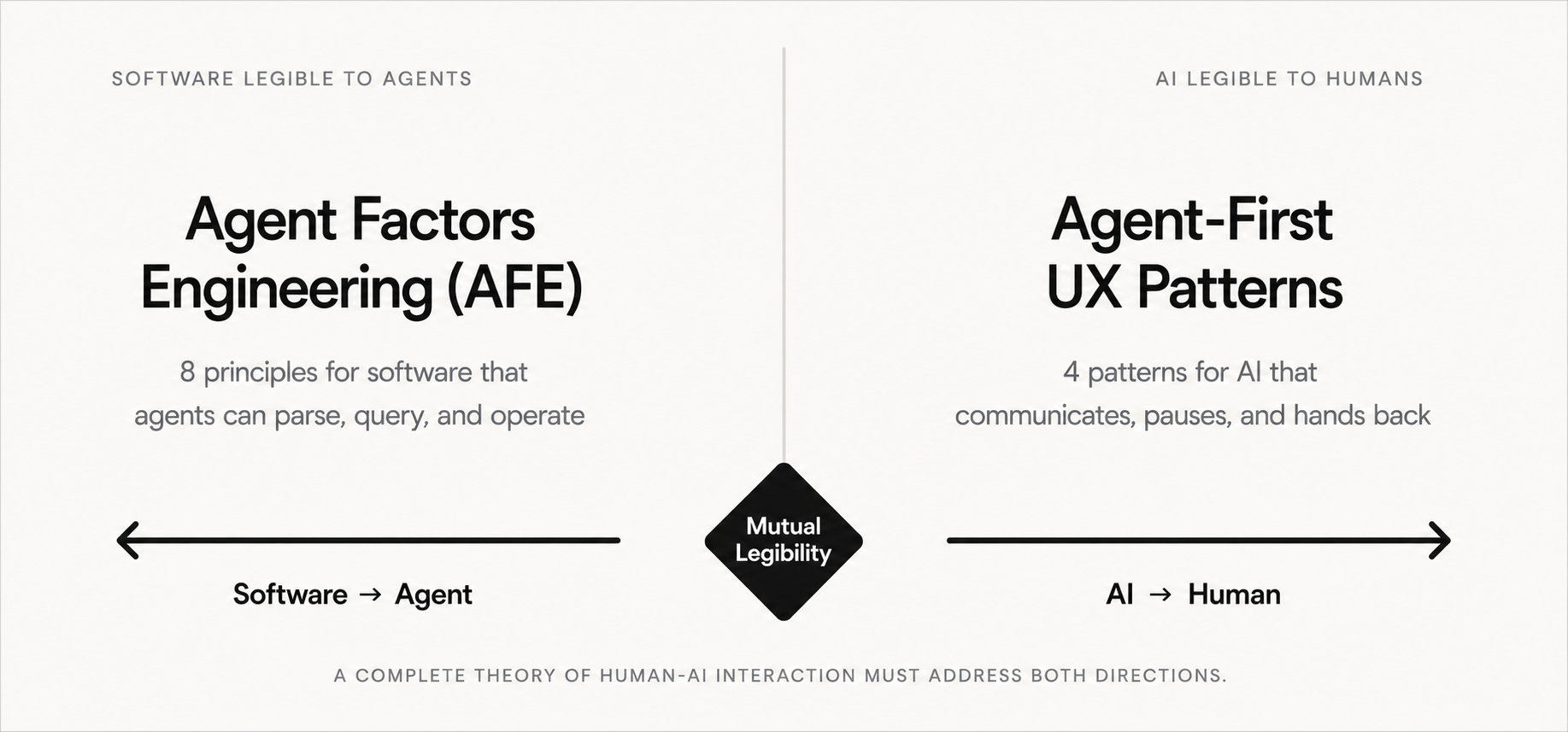
The central design challenge of the agentic era is bidirectional legibility.
Humans need to understand AI systems — what they're doing, why, what they can and can't do, when to trust them. This is the legibility of AI to humans problem, and it's receiving significant attention.
But there's a second problem receiving less attention: AI agents need to understand software. As agents become primary operators of digital systems — not assistants prompting users, but autonomous actors completing tasks — the legibility of software to agents becomes equally important.
A complete theory of human-AI interaction must address both directions. How AI makes itself legible to humans, and how software makes itself legible to agents.
Software is currently designed to be legible to humans. Visual hierarchy communicates importance. Spatial layout communicates relationship. Consistent affordances communicate behaviour. Humans read these signals fluently — they're the product of decades of HFE and UX research.
Agents don't read visual signals. They parse structure. They query APIs. They infer from labels and semantic markup. And when the software doesn't expose those things — when it relies entirely on visual context that agents can't access — agents fail.
AFE addresses the second direction: software legible to agents. The Agent-First UX Patterns address the first: AI legible to humans. Together, they describe the design space of a world where humans and AI genuinely operate together — each understandable to the other.
Framework 04
HFE → AFE: A Lineage
The table below traces how Human Factors Engineering principles from the 1940s–60s prefigure the AFE principles developed for agent-era software. The problems are structurally identical; the user population is different.
| HFE Principle | HFE Problem | AFE Principle | AFE Problem |
|---|---|---|---|
| Feedback | Humans need confirmation that their action had an effect | Status | Agents need machine-readable confirmation of system state |
| Consistency | Humans build mental models from repeated patterns | Machine Readability | Agents build contextual representations from consistent structure |
| Error prevention | Design systems so humans are unlikely to make errors | Defaults | Reduce decisions agents must make; reduce paths to failure |
| Error recovery | When errors occur, make recovery straightforward | Transparency | Explain failure and indicate what the agent should try next |
| Progressive disclosure | Don't overwhelm humans with information they don't need yet | Chunking | Break tasks into discrete, completable units with clear scope |
| Affordance | Make clear what can be done and how | Control | Actionable elements must be identifiable and behave as labelled |
| Visibility of system state | Humans should always know what the system is doing | Status + Transparency | Agents must determine current state without parsing visual feedback |
| Mapping | Controls should correspond logically to their effects | Handoffs | Communicate when tasks cross system or context boundaries |
HFE's core insight — that failures attributed to "user error" are usually failures of system design — applies equally to agent failures. When an AI agent fails to complete a task in a software system, the failure is usually not the agent's. It's the software's. The software wasn't designed to be operable by a machine. That's the problem AFE exists to solve.